





Architektura Blackwell
Grafické karty nové generace od Nvidie – GeForce RTX 5090 a RTX 5080 – sice vyjdou až třicátého, ale už je po embargu a prvních recenzích nejvyššího modelu RTX 5090, který jsme testovali i my. V tomto článku se podíváme na architekturu Blackwell, která tyto nové grafiky pohání, a její nové vlastnosti a funkce. Od DLSS 4 přes architekturu výpočetních jednotek a výbavu čipu až po softwarovou stránku této nové generace.
SM a shadery
Jeden blok SM nadále obsahuje 128 „shaderů“ a 512KB soubor registrů a 128KB L1 cache. Těmto shaderům či shaderovým jednotkám Nvidia nepřesně říká „Cuda jádra“, ale ve skutečnosti v GPU představuje jedno „jádro“ celý blok SM, jednotlivé shaderové jednotky jsou jen „pruhy“ SIMD jednotek tohoto jádra.
Nvidia v této nové architektuře změnila schopnosti shaderových jednotek. Dříve polovina jednotek uměla počítat běžné floating-point operace, které jsou u grafických aplikací výchozím „chlebem“ GPU, druhá polovina přidaná od generace Turing uměla počítat doplňkové celočíselné operace. Od generace Ampere byla tato druhá sada jednotek generalizována a umí jak INT, tak FP operace.
Nyní Nvidia udělala to, že stejné schopnosti dala i první polovině jednotek, takže nyní všechny shadery mohou zpracovat buď INT, nebo FP operaci (nikoliv obojí najednou). Výkon čistě v FP32 operacích se tímto nezmění. Narůst by mohl tehdy, pokud běžící kód obsahuje více než polovinu celočíselných operací, což je asi méně typické, nebo aspoň části, kde INT dominuje.

Těchto 128 shaderů má standardní jednotky podporující 32bitovou přesnost. Separátně jsou v každém bloku SM také jednotky pro výpočty s dvojitou přesností (FP64), ale jsou jen dvě (proti 128 jednotkám FP32/INT32). Operace FP64 tedy GPU umí zpracovávat jen s výkonem 1/64 plného výkonu v FP32 – je to víceméně jen pro kompatibilitu.
Vylepšený Shader Execution Reordering
Vedle toho shadery architektury Blackwell mají vylepšené vykonávání operací mimo pořadí (SER 2.0, neboli Shader Execution Reordering 2.0) proti architektuře Ada Lovelace. Logika provádějící dynamické řazení operací má být až 2× efektivnější (těžko ale říct, jak je to měřeno). SER 2.0 má mít menší režii a lepší schopnost najít příležitosti ke zlepšení výkonu.

Tato schopnost SER není aktivní globálně a neustále, ve výchozím stavu ji GPU nepoužívá a není to tedy úplně ekvivalent out-of-order execution u CPU. Nvidia uvádí, že vývojáři hry mohou SER zapnout volitelně skrze API. Zřejmě nemusí mít vždy pozitivní efekt na výkon, takže využití této technologie je „opt-in“. Vývojáři ji mohou použít pro funkce, u kterých profilováním zjistí, že v nich SER zvýší výkon. Zatím asi není využití této technologie ve hrách zrovna široké (uvedena byla už v GeForce RTX 4000), Nvidia uvádí, že už ji používá „několik her s ray tracingem“.
Neural shadery
Nová u shaderů architektury Blackwell je kompatibilita s tzv. Neural Shadery. Tou jsou operace využívající tensor jádra, ale ne jako samostatnou jednotku, ale přímo ze shaderových programů běžících na shaderech v SM. Funguje to tak, že v takovém shaderovém programu je vlastně volána nějaká předtrénovaná neuronová síť s nějakým poměrně malým modelem.
Toto dříve nebylo možné, protože tensor jádra nebyla s shaderovými jednotkami úzce propojená. Jde to právě až v GPU architektury Blackwell (poznámka: toto je něco, co architektury AMD možná nemusí řešit, protože u nich je alespoň nyní jejich forma akcelerace AI integrovaná do klasických výpočetních jednotek s použitím stejných pracovních registrů a použití klasických shaderových instrukcí a instrukcí WMMA akcelerujících AI v jednom shaderovém programu je nejspíš možné automaticky – nevíme ovšem, zda se tento přístup nezmění u budoucí architektury UDNA).
Stochastic Texture Filtering
Nvidia pro Blackwell navrhuje techniku Stochastic Texture Filtering, která se používá jako určitá náhrada za složitější (trilineární, anizotropické) filtrování a využívá principu, že je výsledek částečně randomizován. Přidání šumu může předcházet artefaktům jako je moiré. Blackwell má pro potřeby této techniky v texturovacích jednotkách 2× vylepšený výkon nefiltrovaného (nearest-neighbor) interpolování. V tomto kontextu je zajímavé, že i architektura AMD RDNA 3.5 (a možná tedy i RDNA 4) přidává podporu pro akceleraci nefiltrované interpolace při texturování, možná také pro toto stochastické filtrování.
Nová tensor jádra: Podpora FP6 a FP4
Tensor jádra jsou už v páté generaci a jejich nová architektura přináší podporu pro operace s přesností FP4. Toto umožňuje provést dvojnásobek operací proti výpočtům s 8bitovou přesností INT8 či FP8. Současně uložení dat modelu o určitém počtu parametrů potřebuje jenom polovinu kapacity paměti proti modelu s 8bitovou přesností.
Ale nevýhodou je extrémně nízká přesnost těchto hodnot, respektive je otázka, zda se o přesnosti ještě dá mluvit. FP4 by mělo dávat jen dva bity (čili jen čtyři možné hodnoty) pro exponent a jeden bit čili dvě hodnoty pro mantisu, čtvrtý bit je znaménko. Zdá se ale, že pro AI využití je navrhován i formát s 3bitovým exponentem a žádnou mantisou. Báze by měla být stále dva, jde stále o binární floating-point čísla. Takovéto datové typy lze možná chápat spíš jako cosi na pomezí expresivnějšího upgradu logické hodnoty true/false (což je jednobitová hodnota) a klasické proměnné ukládající čísla.
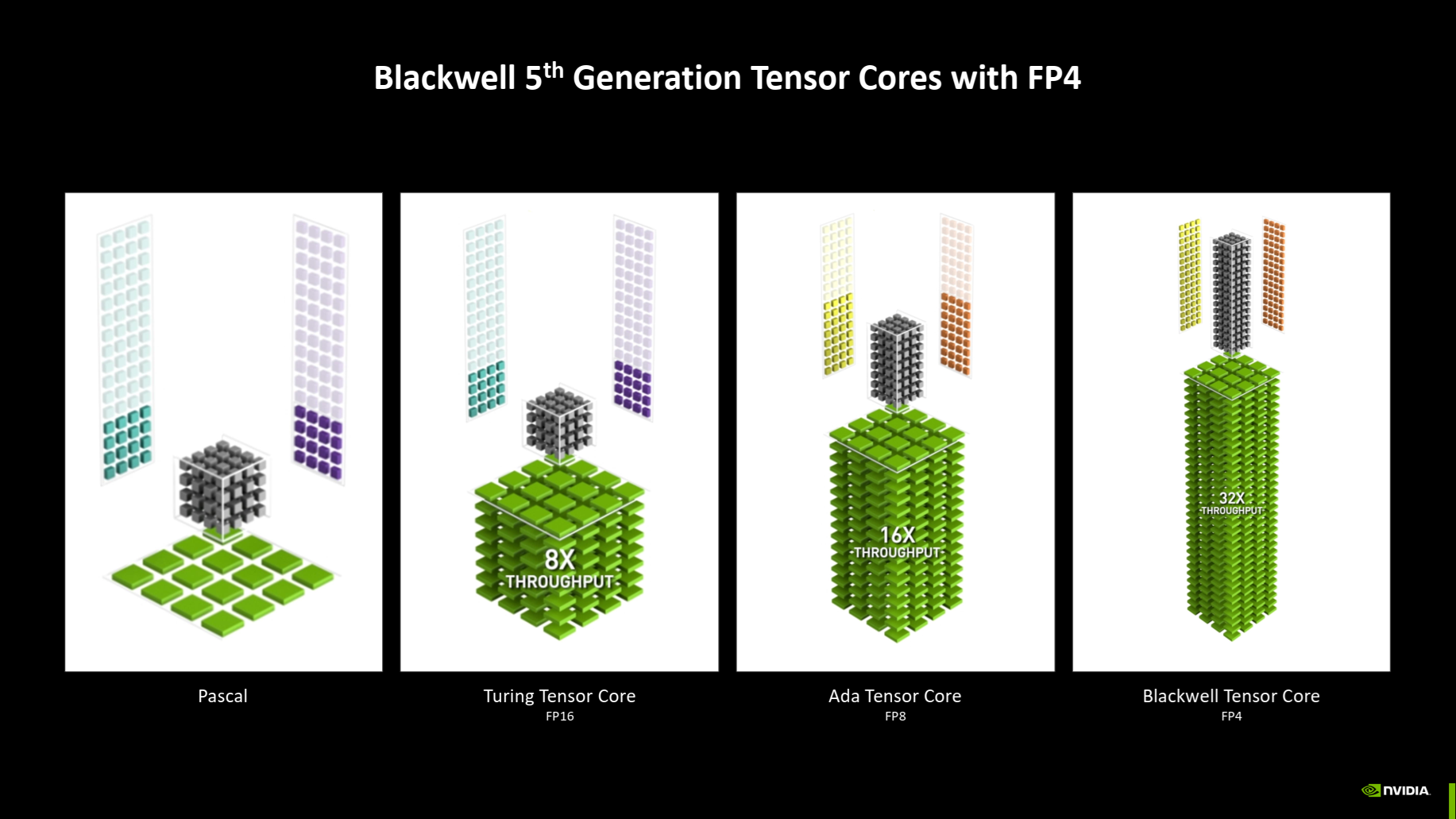
Neuronové sítě (AI modely) jsou obecně překvapivě kompatibilní s nízkou přesností dat – alespoň při inferenci – proti tomu, jakou přesnost byste potřebovali pro obvyklé numerické výpočty. U INT8/FP8 už ale bývá pozorována zhoršená kvalita výsledků, což se u Int4 nebo FP4 musí projevit o to víc. FP4 model se stejným počtem parametrů jako FP8 by asi měl mít horší výsledky. Je proto možné, že použití těchto hodnot bude omezené jen na některé aplikace, nebo se bude muset různě kompenzovat (třeba tím, že v 4bitové přesnosti bude jen část výpočtů, nebo že bude model mít více parametrů). Ono dvojnásobné škálování výkonu tedy asi nemusí být něco automatického.
Jak bylo zmíněno, důležitá může být schopnost s 4bitovými hodnotami vměstnat model o určitém počtu parametrů na GPU s malou pamětí (třeba 32 GB místo 64 GB), ale vždy u toho bude ona nevýhoda horší kvality, takže je otázka, jak kompromisní toto v praxi bude. Alternativou k FP4 ještě může být datový typ FP6, který Blackwell také nově podporuje. U toho už asi nebude dvojnásobný výkon a jeho smyslem je patrně úspora paměti.
Tensor jádra v herních čipech Blackwell mají po softwarové stránce umět stejný typ neuronových sítí (kterému Nvidia říká transformer engine 2. generace) jako serverová verze Blackwellu GB200.
RT jádra s 2× výpočetním potenciálem
Akcelerátory RT core (jeden v každém bloku SM) jsou u GPU Blackwell ve čtvrté generaci. Jejich hlavní novinkou je dvojnásobná kapacita pro zpracování průsečíků paprsků s trojúhelníky objektů ve scéně za jeden cyklus frekvence. U Ada Lovelace by RT jádro mělo zvládat 4 průsečíky za cyklus, pokud máme správné informace, takže u Blackwellu by to snad mohlo být 8 za cyklus.

Počet zpracovatelných průsečíků paprsků a boxů BVH není uveden, ani není zmíněno jeho zlepšení. To by ale snad nastat mohlo, protože u Ada Lovelace snad také byly podporovány čtyři za cyklus a je divné, že by bylo podporováno méně operací na úrovni pomocných boxů BVH než se samotnými trojúhelníky.
Článek pokračuje na další straně.
⠀
- Contents
- Nová GPU generace Blackwell / RTX 5000
- Architektura Blackwell
- Nové technologie čipů Blackwell
- Software a novinky ve výbavě





