





New shader architecture, how is it with 2× FP32 units
In terms of hardware, September was a green month with the release of the new generation of Nvidia GPUs, GeForce RTX 3000. They are based on the new Ampere architecture. In this article we are going to discuss what’s new compared to Turing: the new SM architecture doubling the number of shaders, the manufacturing process and the characteristics of the two chips that have been unveiled so far.
New SM block and shader architecture
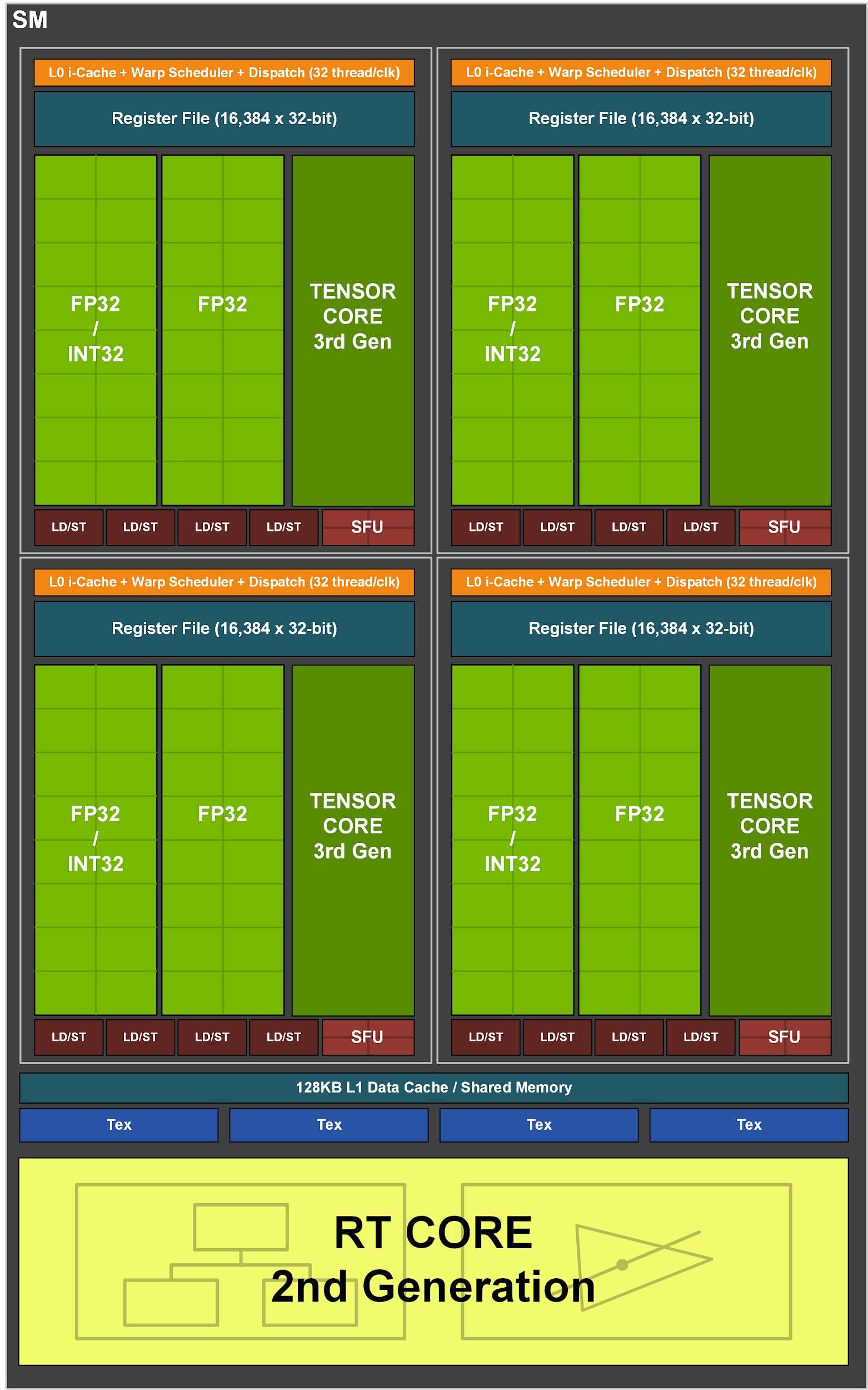
Probably the most important change happened in shaders at the level of SM blocks and is related to the fact that Ampere now advertises 128 instead of 64 shaders (“Cuda cores”) per SM block and the total number of units/Cuda cores has more than doubled. It doesn’t however mean that a single SM in Ampere has twice as much resources and performance, it’s a little more complicated.
In fact, this architecture is a follow-up on the change that Nvidia has already made in the Turing and Volta GPU architectures. Originally, with Maxwell and Pascal, there were 64 shaders in one SM block and these supported FP32 (floating point operations, which are most important in the GPU) and INT32 (integer) instructions. In reality, the structure is such that the SM block contains four subsections each connected to its own warp scheduler and load/store units, and each warp scheduler sends operations to 16 FP32/shader units in form of one single 16-wide SIMD vector (a “warp”). All 16 units compute the same operation (warp) at a time, just operating on different data value. One SM is in other words akin to four 16-wide SIMD units (this is why it’s inaccurate to talk about 64 “Cuda cores”).
Processing two FP32 operations in parallel
In the Volta and Turing architectures, Nvidia has made a big change and added separate INT32 units capable of doing integer-only operations in parallel to FP32 units. Instead of one 16-wide operation (warp) in one cycle, the subsection/warp scheduler in Turing can send two warps to be executed – one FP32 warp to the main units, and if there also is and integer instruction (warp) ready, it sends it to a separate INT32 SIMD unit. In total, the SM block can now process 64 FP32 operations in one cycle as Pascal can, but in addition 64 INT32 operations can be handled in parallel with them. Integer instructions are less common (the ratio to FP ops fluctuates, but say 3:1 on average), but sending them to a parallel unit frees up the FP32 unit for more operations and greatly increases performance per 1 MHz.

And it turns out that the doubling of shaders in Ampere is, in fact, just another modification of this arrangement. Nvidia retained the ability of the SM block (or subsection) to process two operations in one cycle. But this time, there’s not a FP32 unit and INT32 unit connected in parallel, but a FP32 unit and a second unit that can do either INT32 or FP32 operations. Ampere can thus perform two floating point operations per cycle instead of one (which is 2× faster compared to Turing/Volta), or one FP32 and INT32 as Turing/Volta could. However the FP32 + FP32 combination is a more likely to happen in code, so now both of these pipelines (or data paths) will be used most of the time, while in Turing the INT32 pipeline was used perhaps only a half or third of the time.
With this, Ampere significantly increases performance per 1 MHz, but it doesn’t double the performance of Turing. Other bottlenecks can also slow down the computations, but the main reason is that only the FP32 + FP32 scenario has seen 2× performance boost, while in the case when FP32 + INT32 scenario, the performance is the same as for Turing.
Number of shaders in the specifications
Physically, one SM block is still actually made up of four subsections with a warp scheduler sending warps to 16-wide units, but now two of these 16-wide vectors/warps can be executed simultaneously. For Turing, Nvidia has not counted the units for INT32 operations as separate shaders, so those GPUs did not advertise a double number of shaders in their specifications. But since in Ampere this second unit can also execute FP32 instructions, Nvidia now has a reason to count it as a separate shader, and thus now one SM block officially counts as 128 shaders and a GPU with a given number of SMs now has twice as many shaders as it would have with the Turing architecture.
For example, TU104 and GA104 apparently both have 48 SMs, but for Turing this counts as 3072 shaders while for Ampere as 6144 shaders. This has the side effect that performance per one shader probably is higher for Turing GPUs compared to Ampere, although this is hardly important. The overall performance of the GPU or the performance per SM block (that has increased) is what matters.
By the way: this architectural change only applies to the gaming version of the Ampere architecture. Interestingly, the computing Ampere for servers (GA100 chip, Nvidia A100 card) does not use this, its shaders are arranged in the same way as in the Volta architecture, and the total number of shaders is therefore only 64 per SM block for GA100.
New 3rd generation Tensor core
This is not the only change in the SM block. Nvidia has also updated the architecture of Tensor cores used for neural network-based artificial intelligence computations (employed by DLSS) as well as RT cores used for ray tracing.
Tensor cores are reused from the computational version of Ampere and their main new feature is the use of the Structured Sparsity technique, where the core skips calculations upon zero values in the vector during matrix operations (the algorithm itself can round down values close to zero). Other values are then shifted to the spots freed up by ignoring these zeros, thus freeing up the tensor core to do more actual calculations.
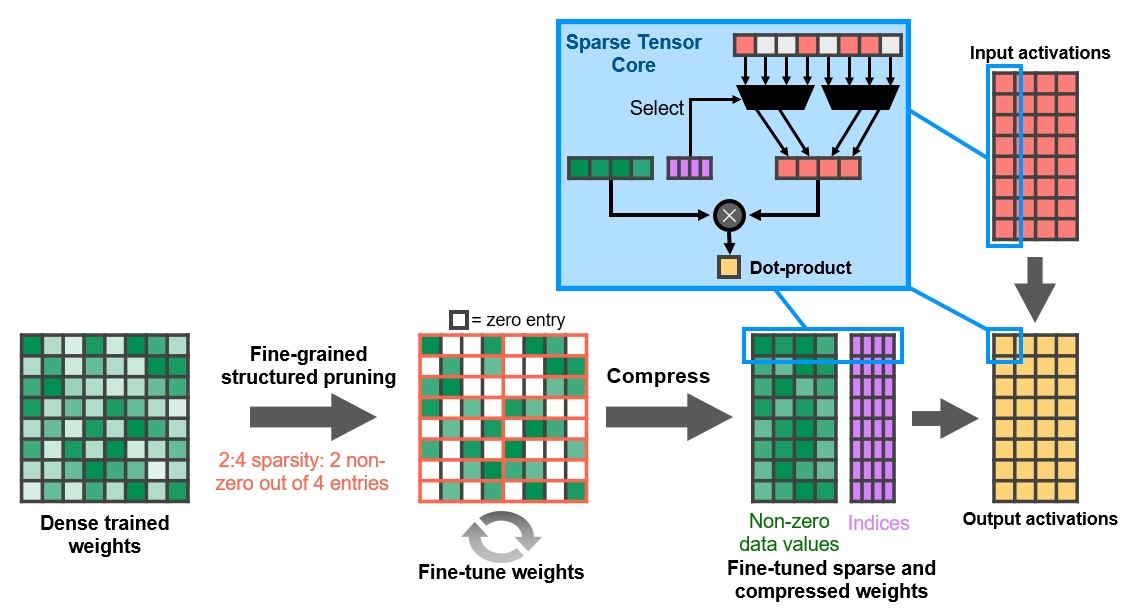
As a result, a given computation is performed with only about half the number of total FMA ops, so the tensor unit now effectively gives the performance equivalent of twice its actual TFLOPS, when Structured Sparsity is used.
There are 4 tensor cores per SM block in the gaming Ampere, each providing 128 FP16 FMA operations per cycle. In Turing, there were eight cores were capable of 64 operations per cycle, so that would boil down to the same unchanged performance. But with the use of the aforementioned Structured Sparsity function, Ampere can offer twice the performance. Based on this, Nvidia states that the performance in artificial intelligence is doubled (or even higher, because Ampere has more SM blocks).

2nd gen RT core
The units used for ray tracing are only present in the second generation in Ampere, not in the GA100 compute chip. Their architecture and operation is probably similar to how they worked in TUring – they still search for ray intersections with bounding volume boxes of the BVH hierarchy and then for intersections with triangles that make up objects of the scene, as defined by the DXR standard within DirectX 12 Ultimate.

However, according to Nvidia, the compute throughput of these cores, which they have to perform these operations, is significantly higher, up to twice as much. Another improvement is that RT cores can now work simultaneously with tensor cores, which was not allowed at Turing, where only one or the other was allowed to be active at a time.
RT cores can do hardware acceleration of motion blur effect
In addition to this performance improvement, the RT core in Ampere supports another new feature. Nvidia has built in the ability to apply a motion blur effect into its architecture. This can be done when computing the intersection of the beam and the object. The intersection is temporally averaged with the intersections for the previous moments in time, and through this the resulting image is blurred as if the motion blur effect was applied separately.
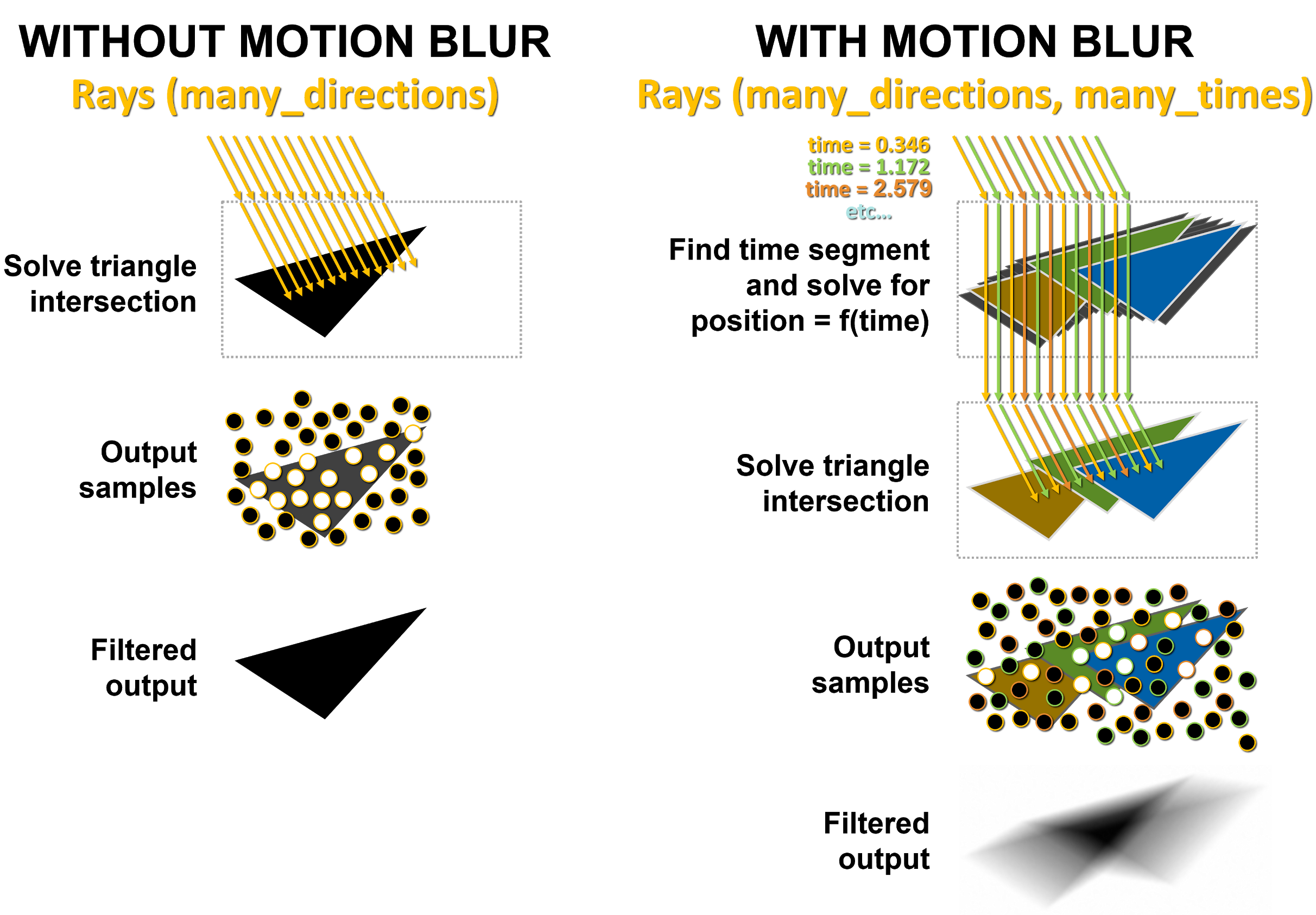
This hardware-accelerated motion blur will naturaly only be possible when ray tracing rendering or ray tracing effect is used in the game, it won’t be usablet when the game is rendered by classic rasterization.
- Contents
- New manufacturing process 8N: Samsung technology enhanced especially for Nvidia
- GA102 and GA104 chips specifications, the first two Ampere units
- New shader architecture, how is it with 2× FP32 units
- PCI Express 4.0, HDMI 2.1, AV1, 8K video and 8K (upscaled) gaming


